

MySQL高级(二)
二、逻辑架构与SQL执行流程
1. 逻辑架构
1.1 服务器处理客服端请求
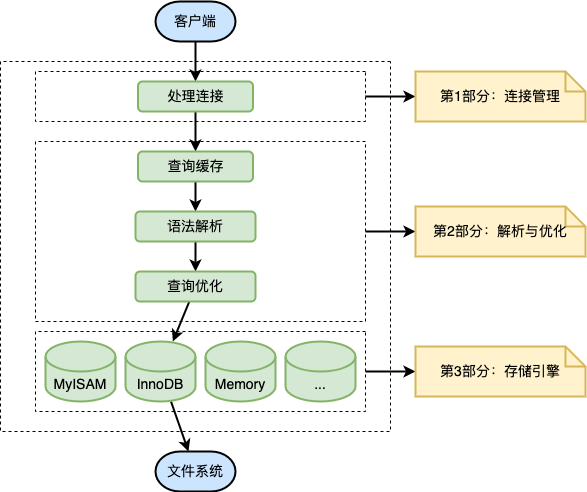
具体内容:
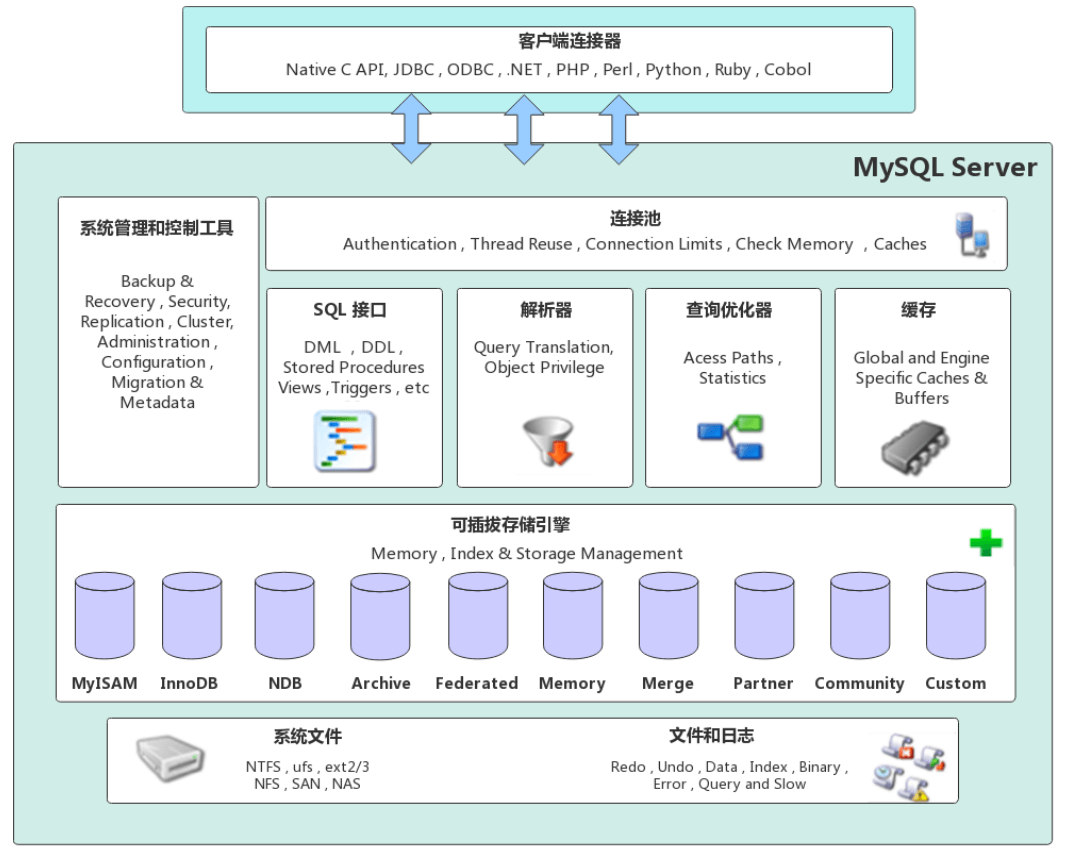
1.2 Connectors
1.3 第1层:连接层
MySQL 服务器对 TCP 传输过来的账号密码做身份认证、权限获取。TCP 连接收到请求后,必须要分配给一个线程专门与这个客户端的交互。所以还会有个线程池,去走后面的流程。每一个连接从线程池中获取线程,省去了创建和销毁线程的开销。
1.4 第2层:服务层
- SQL Interface:SQL接口
- 接收用户的SQL命令,并且返回用户需要查询的结果。
- Parser:解析器
- 在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建
语法树,并根据数据字典丰富查询语法树,会验证该客户端是否具有执行该查询的权限。
- 在SQL命令传递到解析器的时候会被解析器验证和解析,并为其创建
- Optimizer:查询优化器
- SQL语句在语法解析之后、查询之前会使用查询优化器确定 SQL 语句的执行路径,生成一个 执行计划`。
- 这个执行计划表明应该
使用哪些索引进行查询(全表检索还是使用索引检索),表之间的连接顺序如何,最后会按照执行计划中的步骤调用存储引擎提供的方法来真正的执行查询,并将查询结果返回给用户。 - 使用“
选取-投影-连接”策略进行查询。
Caches & Buffers: 查询缓存组件(8.0弃用)
1.5 第3层:引擎层
插件式存储引擎层( Storage Engines),真正的负责了MySQL中数据的存储和提取,对物理服务器级别维护的底层数据执行操作,服务器通过API与存储引擎进行通信
1.6 第4层:存储层
所有的数据,数据库、表的定义,表的每一行的内容,索引,都是存在 文件系统 上,以 文件 的方式存在的,并完成与存储引擎的交互。当然有些存储引擎比如InnoDB,也支持不使用文件系统直接管理裸设备,但现代文件系统的实现使得这样做没有必要了。在文件系统之下,可以使用本地磁盘,可以使用 DAS、NAS、SAN 等各种存储系统。
1.7 小结
简化为三层结构:
- 连接层:客户端和服务器端建立连接,客户端发送 SQL 至服务器端;
- SQL 层(服务层):对 SQL 语句进行查询处理;与数据库文件的存储方式无关;
- 存储引擎层:与数据库文件打交道,负责数据的存储和读取。
2. SQL执行流程
2.1 MySQL中的SQL执行流程
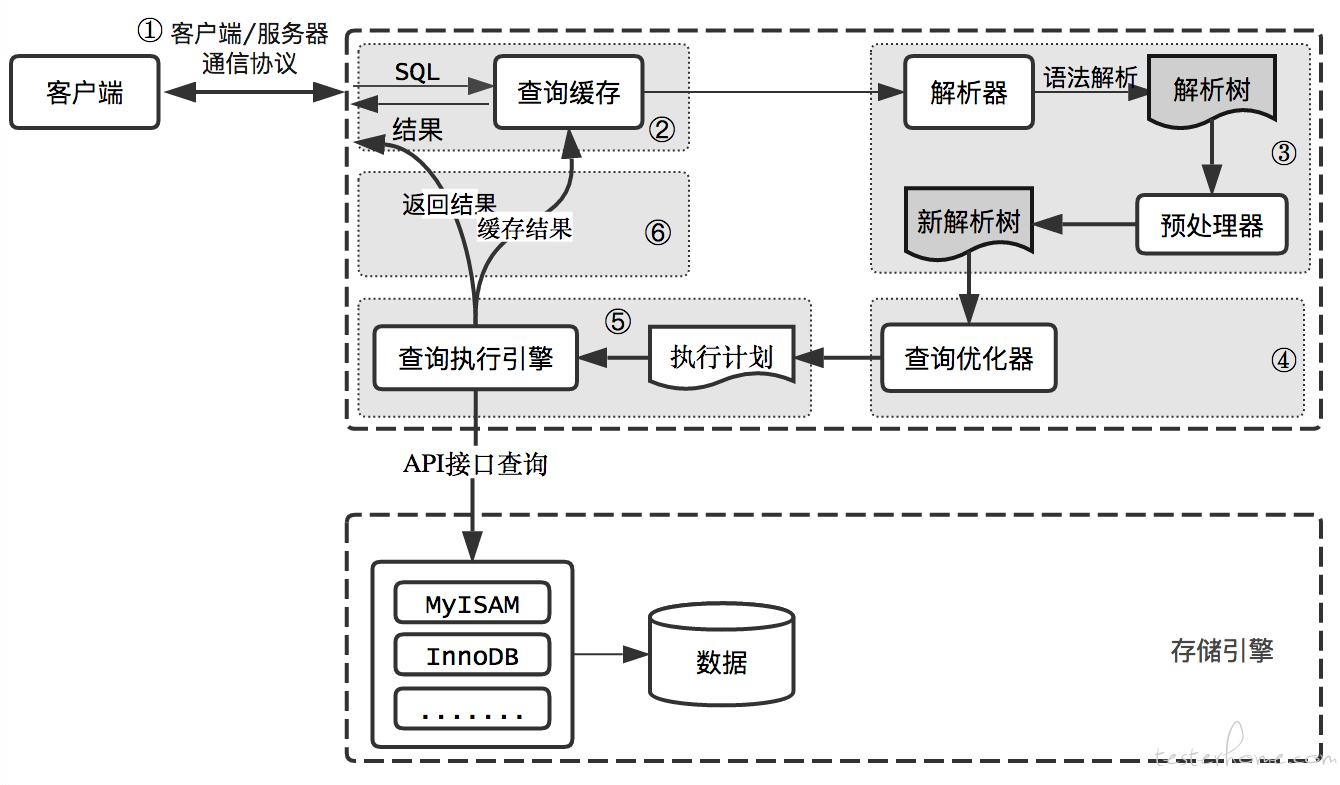
MySQL的查询流程:
1. 查询缓存:(8.0弃用)
**2. 解析器:**在解析器中对 SQL 语句先进行词法分析。再做语法分析,判断输入的SQL语句是否满足MySQL语法。
举例:
select department_id,job_id,avg(salary) from employees group by department_id;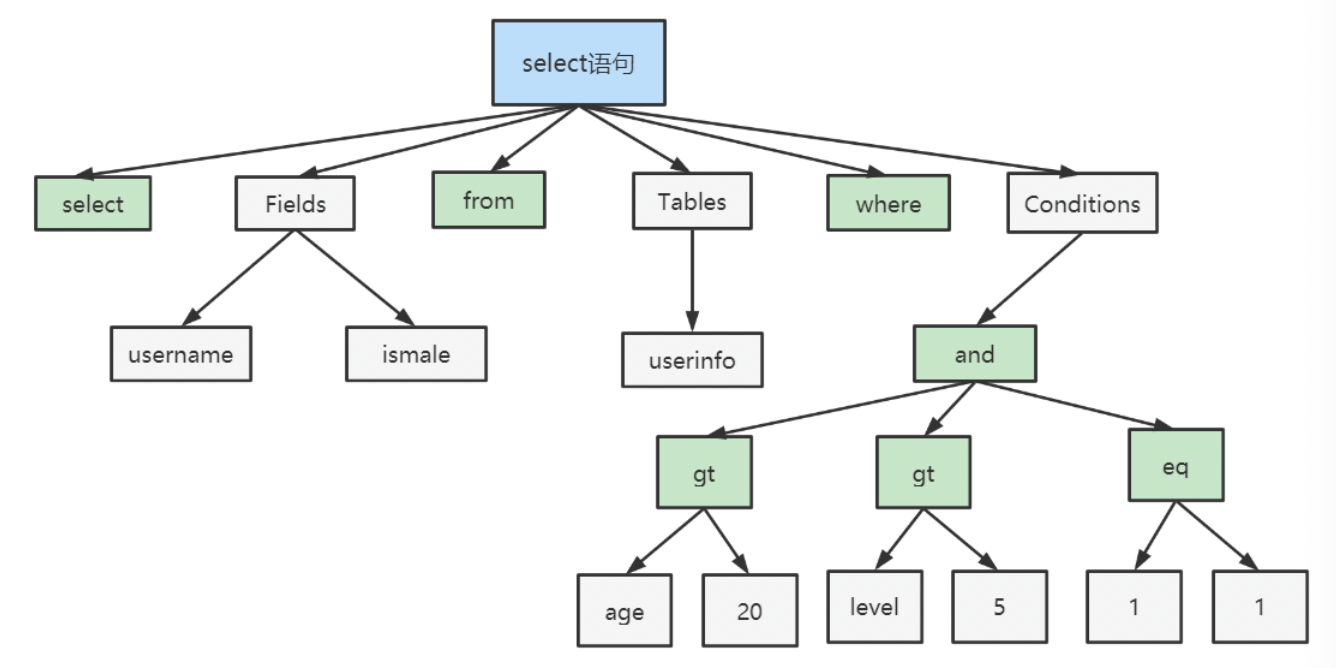
**3. 优化器:**在优化器中会确定 SQL 语句的执行路径,产生执行计划。在查询优化器中,可以分为 逻辑查询 优化阶段和 物理查询 优化阶段。
**4. 执行器:**在执行之前需要判断该用户是否 具备权限 。如果没有,就会返回权限错误。如果具备权限,就执行 SQL 查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
5. 总结:SQL语句->查询缓存->解析器->优化器->执行器。

2.2 查看执行流程命令
# 8.0
mysql> select @@profiling;
mysql> show variables like 'profiling';
mysql> set profiling=1;
mysql> show profiles; # 显示最近的几次查询
mysql> show profile [cpu,block_io] for query 6;
# 5.7
# 在 /etc/my.cnf 中新增一行:query_cache_type=1
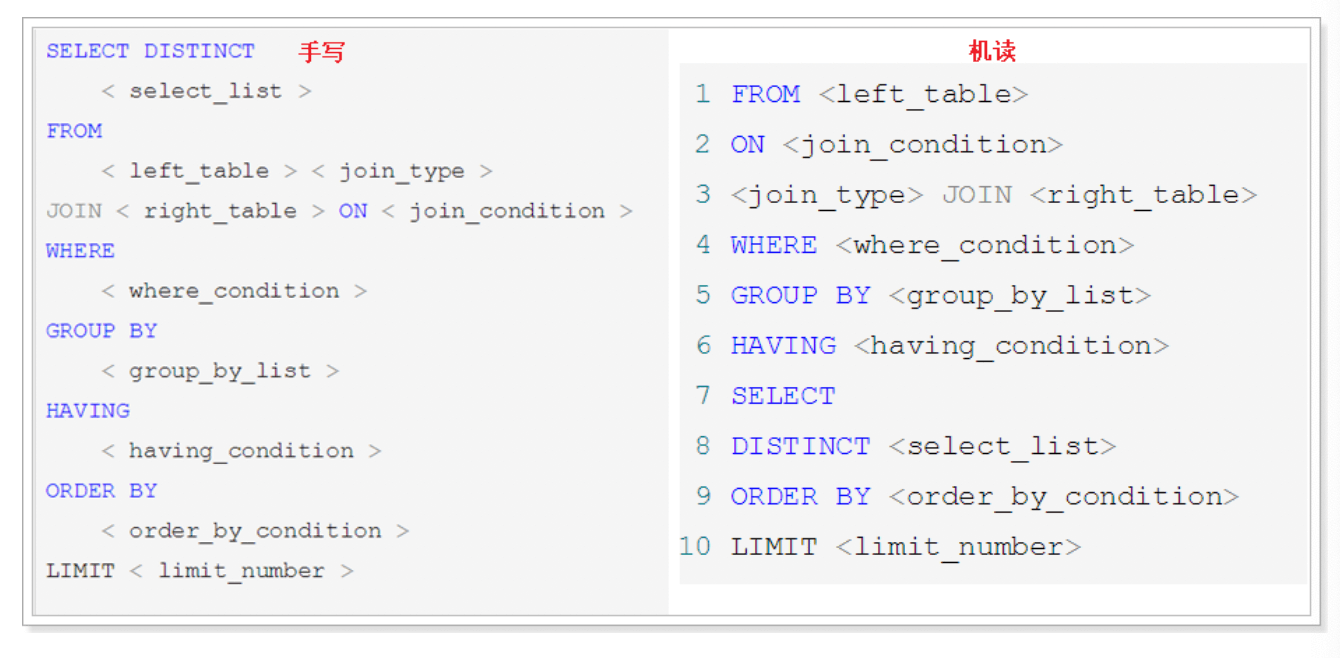
2.3 SQL语法顺序
3. 数据缓冲池(buffer pool)
InnoDB存储引擎是以页为单位来管理存储空间的,我们进行的增删改查操作其实本质上都是在访问页面(包括读页面、写页面、创建新页面等操作)。而磁盘 I/O 需要消耗的时间很多,而在内存中进行操作,效率则会高很多,为了能让数据表或者索引中的数据随时被我们所用,DBMS 会申请占用内存来作为数据缓冲池,在真正访问页面之前,需要把在磁盘上的页缓存到内存中的BufferPool 之后才可以访问。这样做的好处是可以让磁盘活动最小化,从而
减少与磁盘直接进行 I/O 的时间。如果索引的数据在缓冲池里,那么访问的成本就会降低很多。
3.1 缓冲池 vs 查询缓存
-
缓冲池(Buffer Pool):Redo Log & Undo Log能保证数据同步
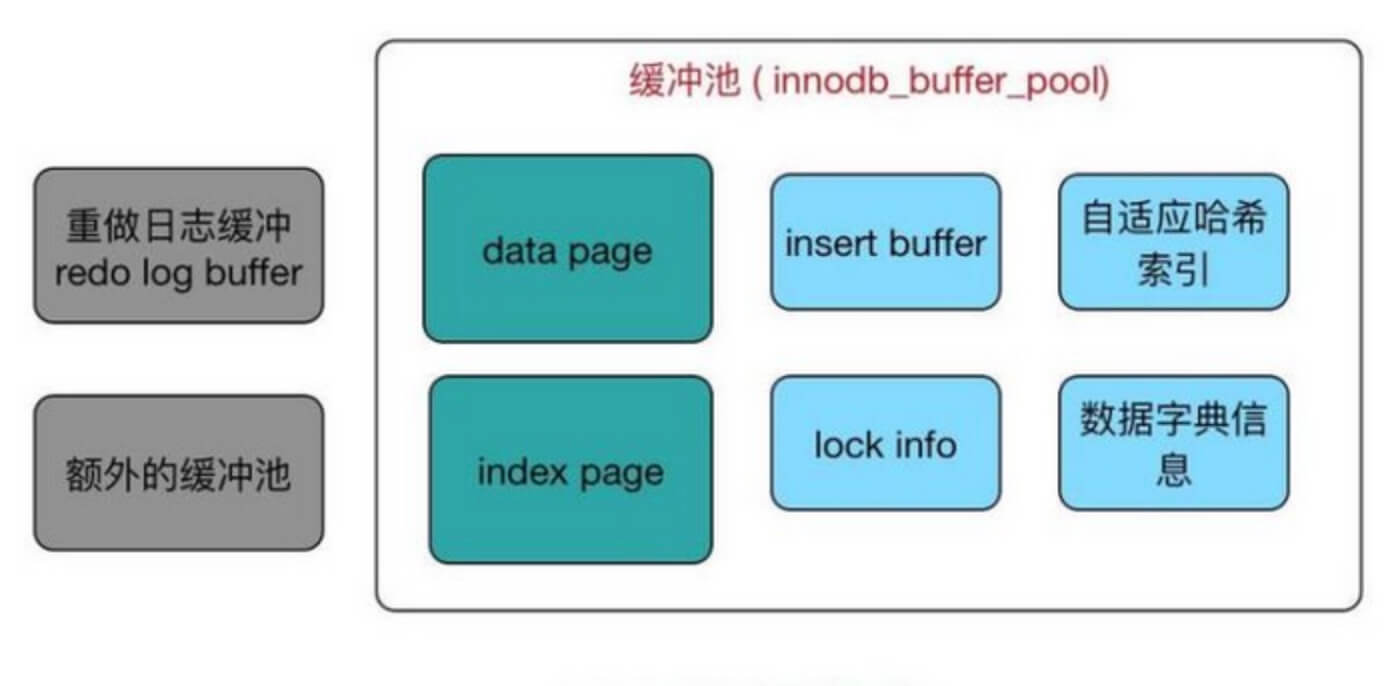
缓存原则:
位置*频次 -
查询缓存:仅仅缓存结果
3.3 查看设置缓冲池大小
show variables like 'innodb_buffer_pool_size';
set global innodb_buffer_pool_size = 268435456; # 256MB
# 配置文件
[server]
innodb_buffer_pool_size = 268435456
# 缓冲池实例个数
[server]
innodb_buffer_pool_instances = 2
show variables like 'innodb_buffer_pool_instances';
# 每个实例大小 innodb_buffer_pool_size/innodb_buffer_pool_instances